
Forest Measurement and Modelling.
|
|
Plot and stand area Forest Measurement and Modelling. |
     |
|
The determination of plot and stand area is critical in the quantification of forests. The area of a sample plot must be accurately determined to allow the determination of per ha mean values (e.g. stand basal area, volume/ha, etc.) The area of the stand or forest is needed to allow the sample statistics to be expanded to estimate forest totals. |
|
| Horizontal distance |
 Area is calculated from an orthogonal projection, i.e. the area in a horizontal plane, not a sloping plane. Thus, any measurements of length (e.g. the length of the side of a rectangular plot) need to be the horizontal distance and not the slope distance. Over short distances horizontal distance can be measured directly with a measuring tape held horizontally. This approach is often called step chaining because long distances can to covered using a number of short horizontal steps. Area is calculated from an orthogonal projection, i.e. the area in a horizontal plane, not a sloping plane. Thus, any measurements of length (e.g. the length of the side of a rectangular plot) need to be the horizontal distance and not the slope distance. Over short distances horizontal distance can be measured directly with a measuring tape held horizontally. This approach is often called step chaining because long distances can to covered using a number of short horizontal steps.Over longer distances or steep slopes, horizontal distance is determined indirectly from the slope distance and the angle of the slope. Horizontal distance = Slope distance * Cos(Q) Note that many computers use radians and not degrees for trigonometrical operations. Radians = Degrees * PI / 180 
|
| Plot area |
Plots are normally laid out as regular geometric shapes. The choice of geometric shape is often controlled by convention although circular plots are common in natural forests while rectangular plots are common in plantations. Rectangular plots where the ratio of long : short side is much greater than 2:1 are called striplines or transects.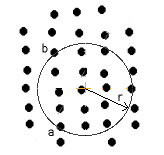 The area of a circular plot is simply calculated as plot radius squared times PI. On sloping ground, the radius should be measured using step chaining where possible to get the horizontal distance. If step chaining is not feasible, use the slope distance to establish the plot and then determine the maximum slope (Q) that crosses the plot from the edge through the centre. Move uphill to the plot edge and sight through the plot centre to the opposite edge and measure the slope. Move to a new position and check for the maximum slope. Multiply the plot area by Cos(Q) to correct the sloping area to the horizontal area. The area of a circular plot is simply calculated as plot radius squared times PI. On sloping ground, the radius should be measured using step chaining where possible to get the horizontal distance. If step chaining is not feasible, use the slope distance to establish the plot and then determine the maximum slope (Q) that crosses the plot from the edge through the centre. Move uphill to the plot edge and sight through the plot centre to the opposite edge and measure the slope. Move to a new position and check for the maximum slope. Multiply the plot area by Cos(Q) to correct the sloping area to the horizontal area. 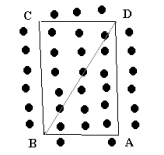 It is difficult to establish rectangular or square plots. The internal angles are rarely exactly 90 degrees, and thus a parallelogram, trapezium or trapezoid rather than a rectangle is actually a more common shape for plots with straight edges. The most reliable way of determining the area of this shape is to treat the plot as two triangles (ie triangle ABD and BCD). The horizontal length of the sides of these triangles is measured using step chaining or trigonometry and then the area determined and added together. To ensure an accurate measurement of area, the opposite diagonal (AC) can be measured and the area of the alternate two triangles (ABC, CDA) can be determined. The area of ABD+BCD should equal ABC+CDA (to an appropriate degree of precision). It is difficult to establish rectangular or square plots. The internal angles are rarely exactly 90 degrees, and thus a parallelogram, trapezium or trapezoid rather than a rectangle is actually a more common shape for plots with straight edges. The most reliable way of determining the area of this shape is to treat the plot as two triangles (ie triangle ABD and BCD). The horizontal length of the sides of these triangles is measured using step chaining or trigonometry and then the area determined and added together. To ensure an accurate measurement of area, the opposite diagonal (AC) can be measured and the area of the alternate two triangles (ABC, CDA) can be determined. The area of ABD+BCD should equal ABC+CDA (to an appropriate degree of precision).  A diamond plot is often used in the plantations of New Zealand. It is like a regtangular plot with one diagonal aligned with the planted row of trees. Calculation of area is identical with the above plot shape. A diamond plot is often used in the plantations of New Zealand. It is like a regtangular plot with one diagonal aligned with the planted row of trees. Calculation of area is identical with the above plot shape.
|
| Forest area |
Many people are surprised by the difficulty encountered in determining the true area of a stand or forest. The boundaries of the forest are rarely well delineated, nor are they consistent between maps, legal documents, remotely sensed images, etc. The error introduced by mistakes in the boundary increases for stands that are not compact (e.g. long linear forests alongside waterways).
|
|
[area.htm] Revision: 6/1999 |